
Data Mining with Text
DATA 503: Fundamentals of Data Engineering
April 8, 2026
Learning objectives
What you should be able to do
- Use core string functions for cleanup and slicing before heavier parsing
- Apply
~/~*andregexp_match/regexp_matcheswith capture groups to pull fields from text - Explain
tsvectorvstsquery, filter with@@, and why GIN indexes matter for search at scale - Produce snippets with
ts_headlineand sort by relevance withts_rank(including length normalization)
Course connection: Logs, tickets, and exports often arrive as prose. Regex and full-text search let you normalize and search near the database when you do not yet have a dedicated search service.
Load the practice data
Tables and sanity checks
| Table | Role |
|---|---|
county_regex_demo |
Regex operator practice |
crime_reports |
Semi-structured police narratives |
president_speeches |
Full-text search (State of the Union) |
Check this:
Expect 5, 79, and 8 respectively.
String functions
Why this layer exists
JSON and arrays get conference talks. Strings pay the rent: addresses, log lines, pasted emails, and CSV columns that are secretly paragraphs. PostgreSQL documents these under String Functions.
Toolkit (high level)
| Need | Examples |
|---|---|
| Case | upper, lower, initcap |
| Trim / measure | trim, char_length, position |
| Slice / replace | left, right, replace |
Demo: cleanup
Run this.
replace is greedy and left-to-right: replace('aaa', 'aa', 'b') yields ba, which surprises everyone exactly once.
Checkpoint: initcap and replace
Task: From the literal ' data engineering ', produce a single row with:
title_phrase:initcapaftertrim(one column)demo_replace:replace('batch-etl-batch', 'batch', 'stream')(shows non-overlapping replacement)
Hint: Nest initcap(trim(...)).
Solution: initcap and replace
Regular expressions
What regex is for
A regular expression describes text shape. PostgreSQL uses POSIX patterns (Pattern Matching). Mind backslashes: you often write '\\d' in SQL so the pattern sees one \.
Notation (compressed)
| Piece | Meaning |
|---|---|
\d |
Digit |
{n,m} |
Repeat between n and m |
() |
Group; also capture for regexp_match |
\| |
Alternation |
^ $ |
Start and end of string (for whole-field tests) |
Operators
| Operator | Meaning |
|---|---|
~ |
Matches (case sensitive) |
~* |
Matches (case insensitive) |
!~ / !~* |
Does not match |
Demo: filter counties
Run this.
WHERE col ~ 'pattern' does not match NULL rows.
Checkpoint: alternation
Task: Return rows from county_regex_demo where county_name matches (lade|lare) case-insensitively. Select county_name only, ordered by name.
Expected: At least Clare County.
Hint: One WHERE with ~* and parentheses.
Solution: alternation
From blob to columns
The crime narrative shape
crime_reports stores original_text blobs. Dates, streets, offense labels, and case numbers sit inside the text, not in typed columns yet.
Run this.
regexp_match vs regexp_matches
regexp_match: first match astext[], orNULLregexp_matches(..., 'g'): one row per non-overlapping match (set-returning)
Run both on crime_id order and compare row 1 (two dates in the narrative).
Capture groups and [1]
Parentheses capture substrings. Index with [1], [2], and so on when you want scalars.
(?: … ) is a non-capturing group: it groups for precedence and repetition but does not add a numbered capture. That is why the case-number pattern uses (?:C0|SO) so the whole token still lands in [1].
If the match fails, the array is NULL and so is [1].
Capturing vs non-capturing (same URL)
Run these and compare the returned arrays.
With capturing (s)?, PostgreSQL puts only the captured substrings in the result array (not the full match first). Here [1] is 's' when the URL uses https, because that is the first (and only) capture.
With non-capturing (?:s)?, there are no numbered captures left, so regexp_match returns a one-element array: the whole match, 'https://'.
How about this?
Run this for plain http:
Checkpoint: second date
Task: For each crime_id, return the second date in the narrative when it exists. Use regexp_matches with the g flag and pick the second element of the returned array, or use a lateral pattern you trust.
Stretch (optional): Only show rows where two dates exist.
Hint: regexp_matches with g returns one row per match; aggregate or filter on ordinality if you use WITH ORDINALITY in a lateral join, or take the second row in a subquery.
Solution: second date
Rows with only one date in the narrative do not appear in this inner join result. LEFT JOIN LATERAL plus NULL would keep those rows if you need them.
Full-text search
Pipeline
Store or compute a tsvector for documents; build a tsquery for the question; @@ is the match predicate. ts_headline formats snippets; ts_rank orders by relevance. A GIN index on the tsvector column keeps @@ from scanning every row.
Types and functions (short)
| Piece | Role |
|---|---|
to_tsvector('english', text) |
Tokenize, drop stop words, stem |
to_tsquery / plainto_tsquery |
Build a query (&, \|, !, <->, <N> in to_tsquery) |
@@ |
tsvector @@ tsquery |
plainto_tsquery is handy for simple keyword boxes; to_tsquery shows operators explicitly.
GIN in one minute
GIN is an inverted index: lexeme to row lists. It fits @@ on tsvector. B-trees do not. Writes cost more than raw text; bulk load then create index is a common pattern.
The setup script already adds search_speech_text and a GIN index on president_speeches.
Demo: match and snippet
Run this.
Filter with @@ first; ts_headline is presentation on matching rows.
Demo: rank with normalization
Run both and compare top five ordering.
SELECT president, speech_date,
ts_rank(search_speech_text, to_tsquery('english', 'war & security')) AS r0
FROM president_speeches
WHERE search_speech_text @@ to_tsquery('english', 'war & security')
ORDER BY r0 DESC
LIMIT 5;
SELECT president, speech_date,
ts_rank(search_speech_text, to_tsquery('english', 'war & security'), 2)::numeric AS r2
FROM president_speeches
WHERE search_speech_text @@ to_tsquery('english', 'war & security')
ORDER BY r2 DESC
LIMIT 5;Flag 2 divides by document length so long speeches do not always win.
Checkpoint: economy and jobs
Task: Find speeches where economy and jobs both match (use to_tsquery with &). Return president, speech_date, and a ts_headline on speech_text for the query. Sort by ts_rank with normalization flag 2 descending; limit 10 rows.
Hint: Single to_tsquery('english', 'economy & jobs') for filter, headline, and rank.
Solution: economy and jobs
SELECT president,
speech_date,
ts_headline(
speech_text,
to_tsquery('english', 'economy & jobs'),
'StartSel = <, StopSel = >, MinWords=5, MaxWords=10, MaxFragments=1'
),
ts_rank(
search_speech_text,
to_tsquery('english', 'economy & jobs'),
2
)::numeric AS relevance
FROM president_speeches
WHERE search_speech_text @@ to_tsquery('english', 'economy & jobs')
ORDER BY relevance DESC
LIMIT 10;Summary
Techniques in one place
| Technique | Use it when |
|---|---|
trim, left, replace |
Normalize display and prep for parsing |
~ / ~*, regexp_match |
Filters and first structured pull from text |
regexp_matches(…, 'g') |
Every occurrence; drive lateral or counting |
to_tsvector + GIN |
Searchable document column |
@@, ts_headline, ts_rank |
Filter, snippet, sort |
Choosing a tool
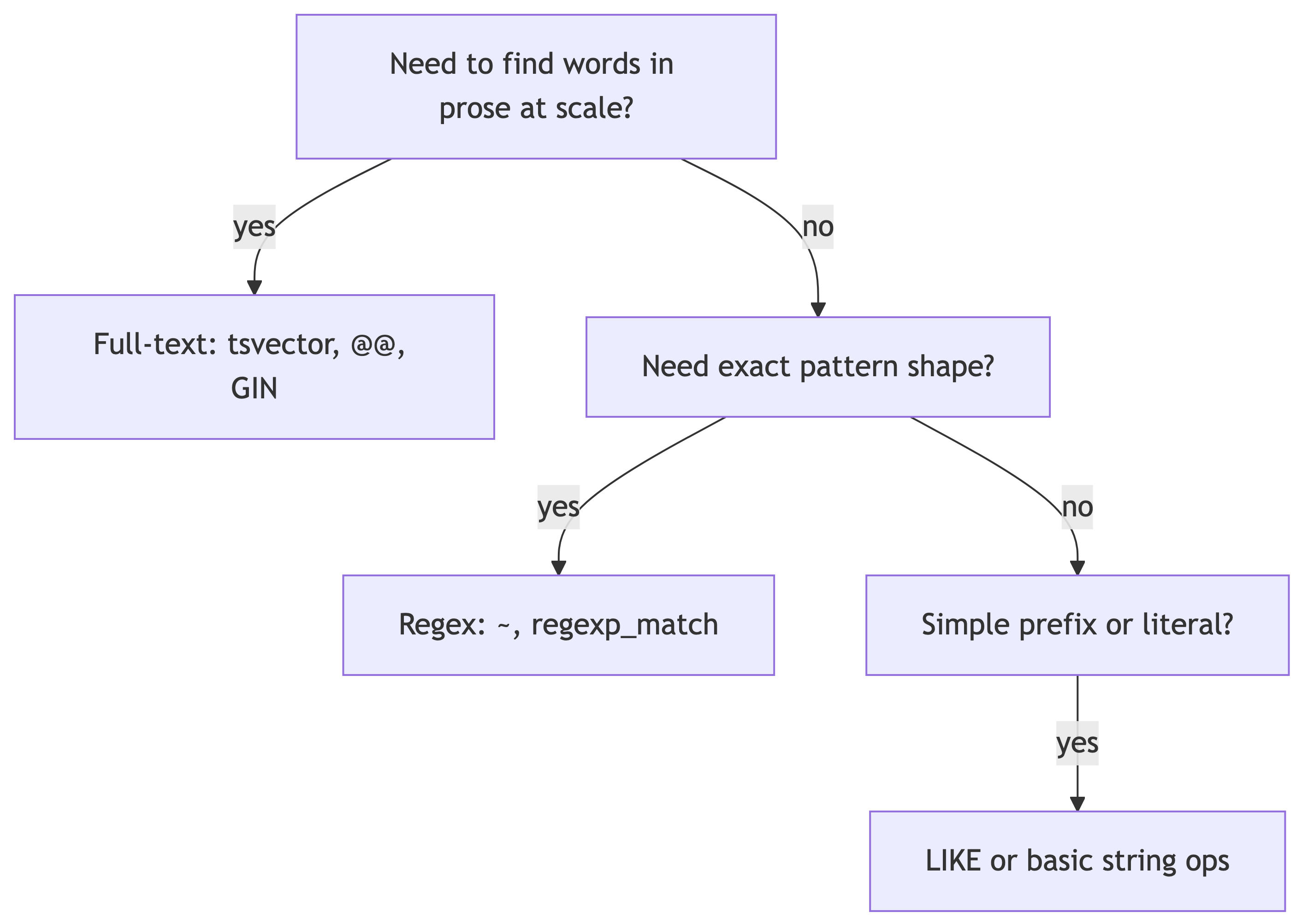
References
- DeBarros, A. (2022). Practical SQL (2nd ed.). No Starch Press. Chapter 14.
- PostgreSQL: Pattern Matching
- PostgreSQL: String Functions
- PostgreSQL: Full Text Search
- PostgreSQL: ts_rank
![]()